
В этом уроке рассмотрим с вами на конкретном примере, как работает функция REGEXP_REPLACE() в DataLens и чем она отличается от обычного REPLACE().
Если вы когда-нибудь сталкивались с задачей замены текста в поле, то наверняка замечали в справочнике функций две на вид похожие функции REPLACE() и REGEXP_REPLACE().
Очень часто у многих возникает вопрос и сомнения, в чем же их различия. Хотя на самом деле все просто. Обычный REPLACE() заменяет конкретные значения (например, буквы К или какой-то конкретный фрагмент текста/числа), то REGEXP_REPLACE() заменяет типы данных. Например, все цифры или буквы на что-то независимо от конкретных значений.
Как это работает?
Давайте на конкретном примере посмотрим, как именно это работает. Предположим, у нас есть список каких-то артикулов.
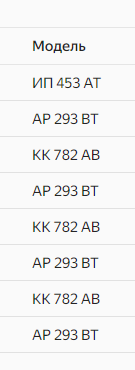
Так вот с помощью функции REGEXP_REPLACE() мы можем в этом списке заменить все цифры на прочерк. Для этого создаем новое поле и прописываем функцию.
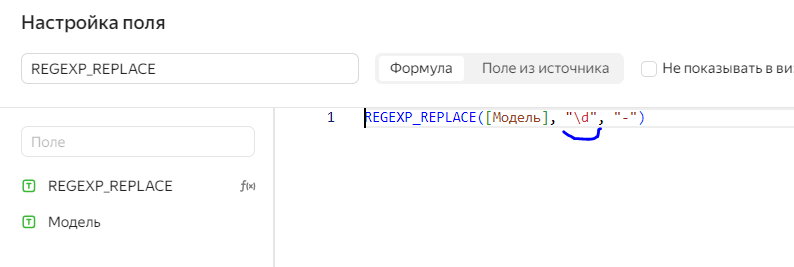
REGEXP_REPLACE([Модель], "\d", "-")Обратите внимание, что в отличие от функции простой замены в среднем аргументе мы указывает не конкретное значение, а тип данных в виде регулярного выражения. Полный список всех регулярных выражений есть на GitHub.
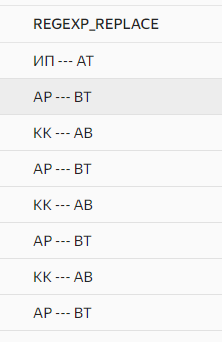
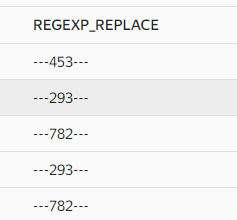
И вот, что мы получаем. Все цифры стали прочерками.
А теперь давайте сделаем наоборот, заменим все, что не число на прочерки. Для этого вместо /d укажем /D.
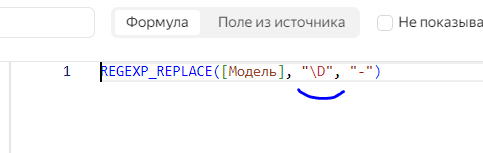
Теперь результат изменился. Все буквы и проблемы стали прочерками.
Вот такая супер полезная функция, которая может очень вам пригодиться в некоторых ситуациях.
Надеюсь, данный урок был вам полезен!
Наши курсы






Более подробно, как это сделать, можно посмотреть ниже.
Если вам понравился урок, то можете поддержать проект по кнопке ниже. Это очень поможет делать для вас больше интересных и полезных выпусков. Спасибо!

Задать вопросы и обсудить волнующие темы про аналитику данных теперь можно на нашем форуме.
Если вам понравился урок, подписывайтесь на канал или группу и ставьте лайки. А также пишите в комментариях свои кейсы или вопросы. Самые интересные мы обязательно разберем.