В этом уроке я покажу, что такое иерархии в DataLens, зачем они нужны и как их сделать.
Итак, для начала давайте разберем, что вообще такое иерархия в DataLens и зачем они нужны.
Немного теории
Иерархическая модель данных — это модель, которая использует представление базы данных в виде древовидной структуры, состоящей из объектов (данных) разных уровней. Между объектами существуют связи, и каждый объект может включать в себя несколько объектов более низкого уровня.
Объекты в иерархической модели данных связаны отношениями «предок» (более близкий к корню) и «потомок» (более низкого уровня). У объекта-предка может быть несколько потомков, в то время как у объекта-потомка есть только один предок. Объекты, имеющие общего предка, называются «близнецами».
Базы данных с иерархической моделью являются одними из старейших и были первыми системами управления базами данных для мейнфреймов. Они разрабатывались в 1950–1960 годах, например, Information Management System (IMS) фирмы IBM.
Примеры иерархических структур данных включают файловую систему компьютера, где корневой каталог содержит иерархию подкаталогов и файлов.
А случае же с DataLens иерархия – это аналог другого известного термина в сфере аналитики Drill Down. Или простыми словами это углубление от общего к частному, от родителя к потомку или от высшего к низшему.
Практический урок
И давайте рассмотрим это на конкретном примере. Допустим, у нас есть некий набор данных, выгрузка, с информацией о закупках в двух компаниях.
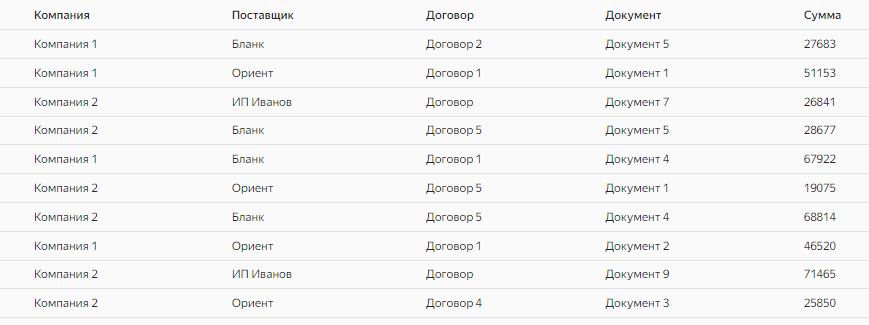
Пока это выглядит как просто список того, по какой компании у кого купили и на какую сумму. Но менеджмент компании хочет получить отчет, где эти данные будут аккумулироваться сначала по компаниям (чтобы сначала видеть общие суммы закупок в целом), затем по поставщикам (чтобы можно было детализировать сумму и увидеть, а у кого вы закупаем больше всего, например), затем по договорам и в конце по документам. При необходимости мы сможет детализировать нашу общую сумму вплоть до документа.
Но задача в том, чтобы сделать это только при необходимости, на дашборде изначально суммы должны быть указаны только по компаниям в целом. Как же это реализовать? Тут нам и помогут иерархии.
Создадим на базе нашего датасета чарт-таблицу. И выберем пункт Добавить–Иерархия.
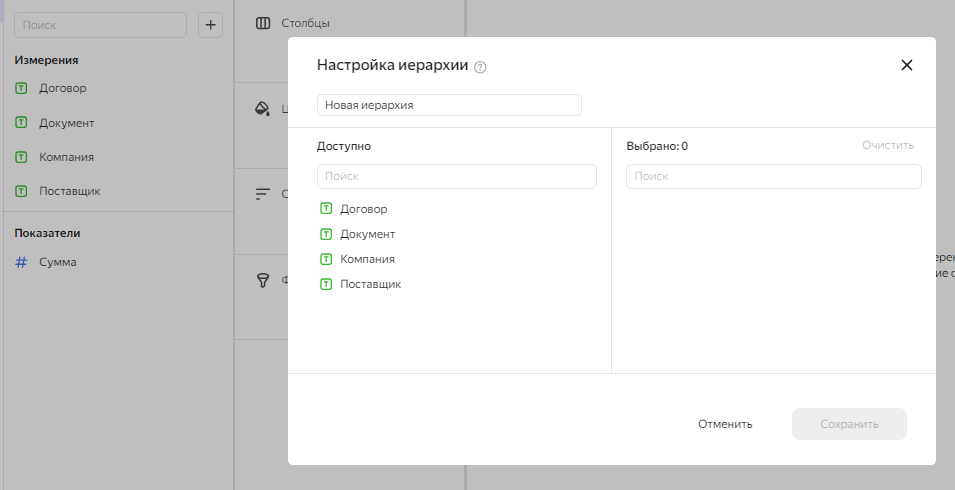
И теперь просто переносим в правую половину поля в той последовательности, в какой они должны детализироваться. У нашем случае это Компания-Поставщик-Договор-Документ.
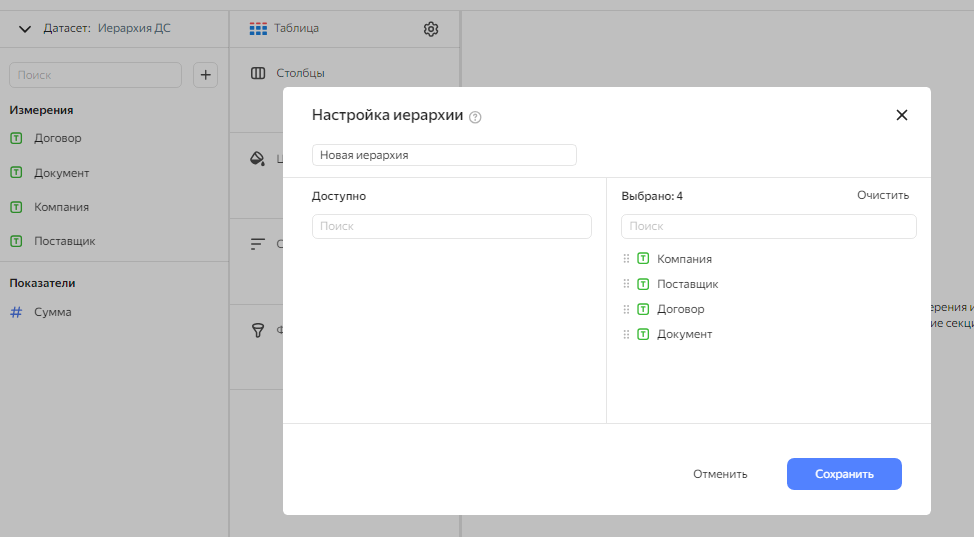
Нажимаем Сохранить и у вас появляется новое поле Иерархия. Перетаскиваем его в колонки чарта. И добавляем сумму.
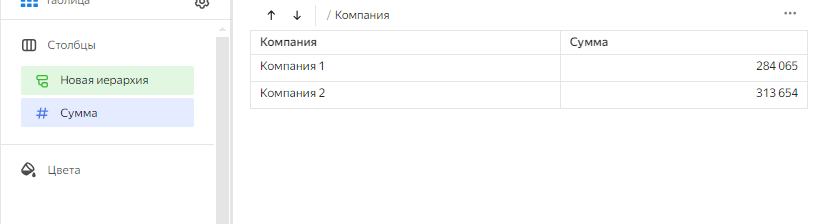
В итоге мы получаем общие суммы закупок в разбивке по компаниям. А как теперь углубиться и посмотреть, что же внутри? Для этого просто щелкаем на нужную строку и проваливаемся в детализацию по поставщикам.
Обратите внимание, что в отличие от древовидной иерархии, тут названия компаний пропадут, а вместо них будет список поставщиков.
Аналогичным образом можно углубиться еще и дойти до документа.

И теперь вам останется просто добавить этот чарт на дашборд. По умолчанию менеджмент будет видеть его с разбивкой по компаниям. А при необходимости сможем самостоятельно провалиться в детализацию и увидеть нужную информацию. Важный момент! При выгрузке в Эксель данного чарта вы получите только две колонки в зависимости от текущей детализации. Всего массива, как в источнике не будет.
Если хотите сами попробовать сделать такой чарт, то ниже можете скачать Эксель источник с данными из урока.
Наши курсы






Более подробно, как это сделать, можно посмотреть тут.
Если вам понравился урок, то можете поддержать проект по кнопке ниже. Это очень поможет делать для вас больше интересных и полезных выпусков. Спасибо!

Задать вопросы и обсудить волнующие темы про аналитику данных теперь можно на нашем форуме.
Если вам понравился урок, подписывайтесь на канал или группу и ставьте лайки. А также пишите в комментариях свои кейсы или вопросы. Самые интересные мы обязательно разберем.